
PDFからテキストをコピーするにはどうしますか?コピーできないことがあるのはなぜ?コピーできないときはどうしたらいいですか?
更新日:

このページの目的
パソコンやスマホの画面に表示しているPDFから文章や数字など(テキストといいます)をコピーして使いたいときがあります。このためにはPDFビューアのテキストをコピーする機能を使うのが簡単です。ただし、コピーされないように保護されたPDFや画像から作成したPDFではテキストのコピーができないので、別の方策が必要です。
ここではPDFからテキストをコピーする方法、コピーできない場合の原因と対策について整理しました。
画面上でテキスト範囲を指定してコピー
PDFを表示するにはPDFビューアのほか、最新のブラウザはWebで配布されているPDFを直接開くことができます。そして、ブラウザで表示している画面からテキストの範囲を指定してコピーできます。例えば、Chromeブラウザは次のようにします。
- (1) 表示しているPDFのページ上で、コピーしたい範囲をマウスで選択します。


- (2) マウスの右ボタンをクリックしてメニューを表示して「コピー」コマンドを選ぶか、コピーしたい範囲を指定した状態でCtrlキー+Cを押すと、選択した範囲のテキストをコピーできます。

- (3) 次に、テキスト編集ソフトの編集画面を表示してペーストすれば終わりです。
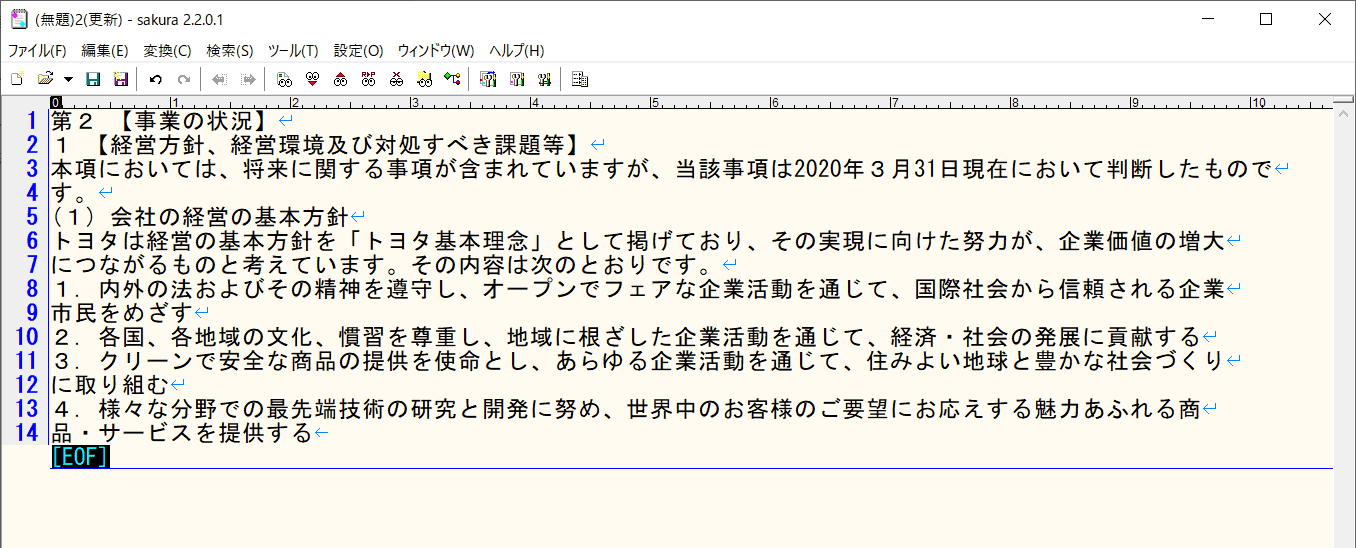
なお、上の例ではペーストしたとき、コピー元PDFの各行の行末位置に改行が入っています。行末に改行が入るかどうかは、ブラウザやPDFビューアによって異なっています。(2020年7月時点)
- 行毎に改行が入る
- Google Chrome(83.0.4103.116)
- Microsoft Edge(83.0.478.58)(Chromiumオープンソースに基づく)
- Adobe Acrobat Reader(Adobe Reader)(2020.009.20067)
- 行毎に改行が入らない(行を繋げる)
- FireFox(78.0.1)
すべてを選択してコピー
Adobe ReaderのようなWindowsアプリケーションでは、メニューに「すべてを選択」コマンドが用意されています。「すべてを選択」コマンドを使うと範囲を指定しないで一括でテキストをコピーできます。
なお、Adobe Readerの「すべてを選択」コマンドでは、PDFの表示しているページ上のすべてのテキスト選択される場合と、Adobe Readerで開いているPDFの全ページに渡るテキストが選択される場合があります。
テキストをコピーできないPDF ― 最も多い理由はPDFの保護
これまでの説明のように、PDFで画面上に表示されているテキストをコピーするのは簡単です。ところが、ときどき、うまく行かないコピーできないケースがあります。
たとえば、次の図のようにAdobe Readerでテキストの範囲を選択して、「編集」メニューを開くと、「コピー」コマンドが有効にならないことがあります。
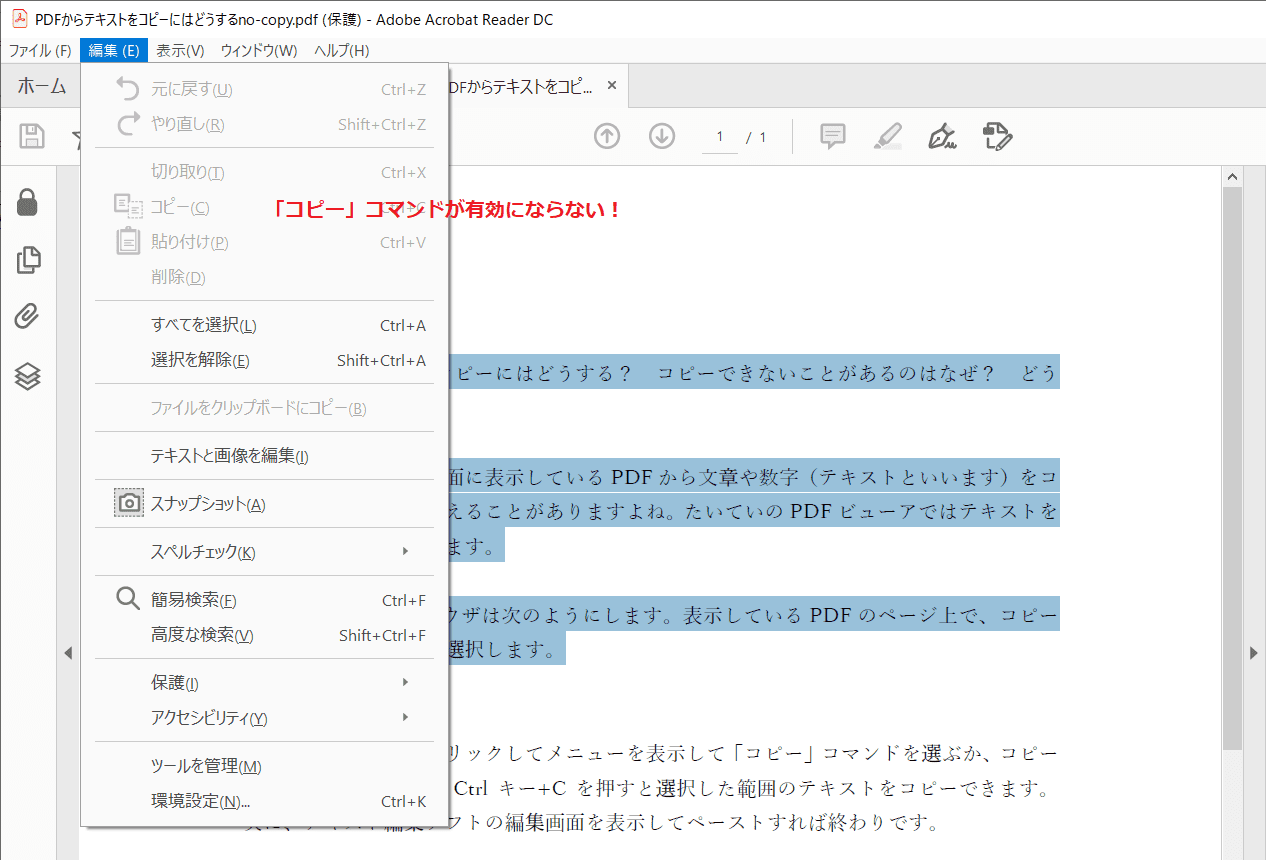
このようなときは、まず、PDFのプロパティをチェックしましょう。Adobe Readerでは「ファイル」メニューの「プロパティ」コマンドで文書のプロパティダイアログを表示し、「セキュリティ」タブを確認します。
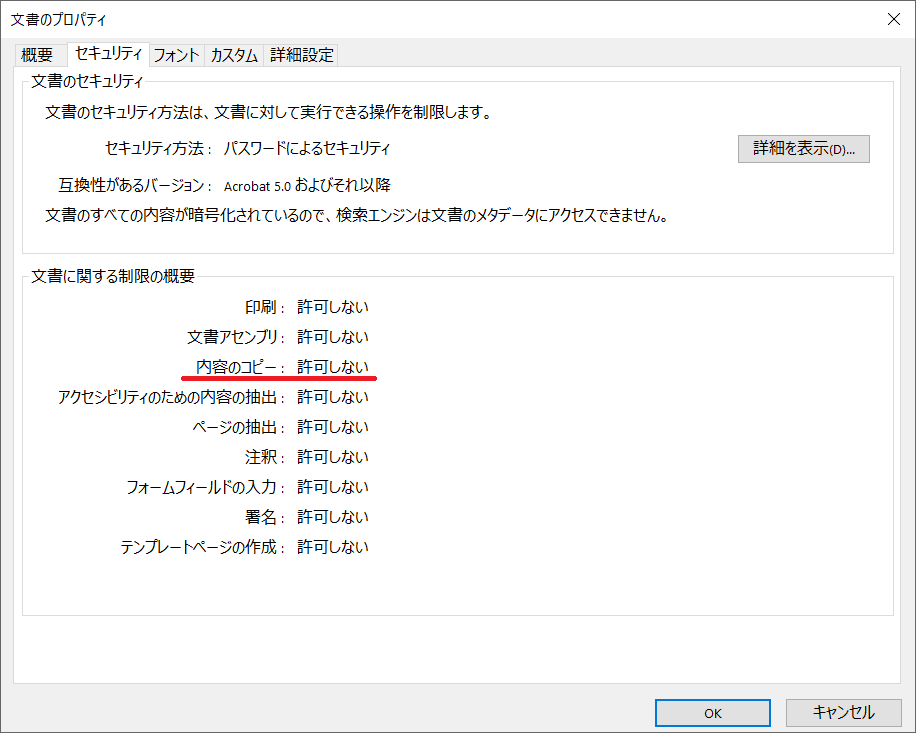
セキュリティタブの「文書に関する制限の概要」のセクションには、PDFファイルの作者によって設定された、PDF利用制限設定(保護)の状態が示されています。「内容のコピー」が「許可しない」に設定されているとテキストや画像などをコピーすることができません。
このようなPDF上のテキストを利用するには、PDF作者からパスワードを入手して保護を解除しなければなりません。それができないときには、PDFを印刷したり、画像に変換したりしたうえで、OCRソフトを使って文字を認識して、テキスト化することになります。
テキストをコピーできないPDF ― その他の理由
PDFのテキストを選択してコピーできないという現象には他に様々な理由が考えられます。
例えば、印刷された文書をスキャナーで読み込んだ画像をPDFにしたもの、あるいはPDFの中の文字がテキストとして扱われていない場合などです。こうしたPDFもOCRソフトを使って文字をテキスト化することになります。
また、まったくコピーできない現象だけではなく、正しくコピーできないという現象もあります。こうした現象についてのより詳しい解説は、「簡単そうで簡単ではないPDFのテキスト抽出」にありますので、ご参照ください。
