DITA 超入門

DITA入門 しくみと概念
DITAとは、ドキュメント記述・管理のための「しくみ」です。この「しくみ」の目的と、基本的な概念を紹介します。
DITAとは
DITA(Darwin Information Typing Architecture)は元はIBMが策定した、「技術文書」(テクニカルドキュメント)を記述・管理するための仕様で、その後、この仕様は構造化情報の標準化団体であるOASIS(Organization for the Advancement of Structured Information Standards)[1]に寄贈され世界標準の仕様となりました。
DITAはXML(Extensible Markup Language)[2]文書として記述します。 XMLは、HTMLのように文書にタグ付けをする言語ですが、HTMLとの大きな違いとして「文書の決まりを自分で作れる」という特徴があります。作った決まりをみんなで共有し、使えるようにすることを「標準化」といいます。つまり、DITAは実際の文書としては「DITAという決まりに従ったXMLで書かれたファイル群」となります。
どんな文書、または文書のどの部分を作るのに効果的か
DITAの目的は次の3つです。
- データ再利用性の向上
- ワンソースマルチユース
- 翻訳の効率化
これらはどれも絡み合った話ですので、あえて3つに分けることもないかと思いますが、DITAはこれらを実現するために考えられた仕様です。
よって、DITAは次の特徴を持つ文書、または文書の一部に対し効果的です。
- 複数の箇所で共通する説明がある
- 複数の製品で共通する説明がある
- 多言語で用意する必要がある
- 様々な対象向けに少しずつ異なった出力を用意する必要がある
- 様々な媒体向けに出力を変える必要がある
- 微細な変更が広範に、頻繁に行われる
つまり、次のような課題を抱えている方々はDITA採用を検討する価値がおおいにあるということです。
- 似たような製品を複数製造しているけれど、それぞれの製品のマニュアルをすべて個別に作っている
→大多数の共通箇所はひとつにまとめたい - 住所や電話番号・部署名が変わったとき、数多くのマニュアルを改修するのがとても大変だった
→小さな変更は小さな労力で済ませたい - いままでは紙のマニュアルだけだったけれど、これからはHTMLでも作らないといけなくなった
→紙マニュアルのデータをHTMLでも流用したい - 毎年マニュアル改訂があるけれど、翻訳にかける時間を短くしたい
→改定のあった箇所のみを翻訳したい
しかし、DITAという仕様を「採用しただけで」は挙げた課題は解決しません。 DITAを使って課題を解決するためには、DITAで用いる「トピック」や「マップ」の概念を理解し、それに合わせたライティング/オーサリング手法を使うことが重要です。
DITAを構成する基本概念「トピック」と「マップ」
マニュアルなどは、最終的には印刷物やHTML文書など、何らかのドキュメントの形を取る必要があります。
DITAにおけるドキュメントは、(複数の)「トピック」と(複数の)「マップ」を組み合わせて構成します。
トピック
トピックにはドキュメントのコンテンツを記述します。たとえば次のようになります。
<topic id="GoalOfDITA">
<title>DITAのめざすもの</title>
<body>
<p>DITAの目的は次のとおりです</p>
<ul>
<li>データ再利用性の向上</li>
<li>ワンソースマルチユース</li>
<li>翻訳の効率化</li>
:
:
</ul>
</body>
</topic>
雰囲気的にはHTMLにそっくりです。ハードルは高くないでしょう。
トピックの構造を図化すると次のようになります。まずは「構造で決められた場所に、当てはまる内容を書く」という見方をしてみると取り組みやすくなるでしょう。
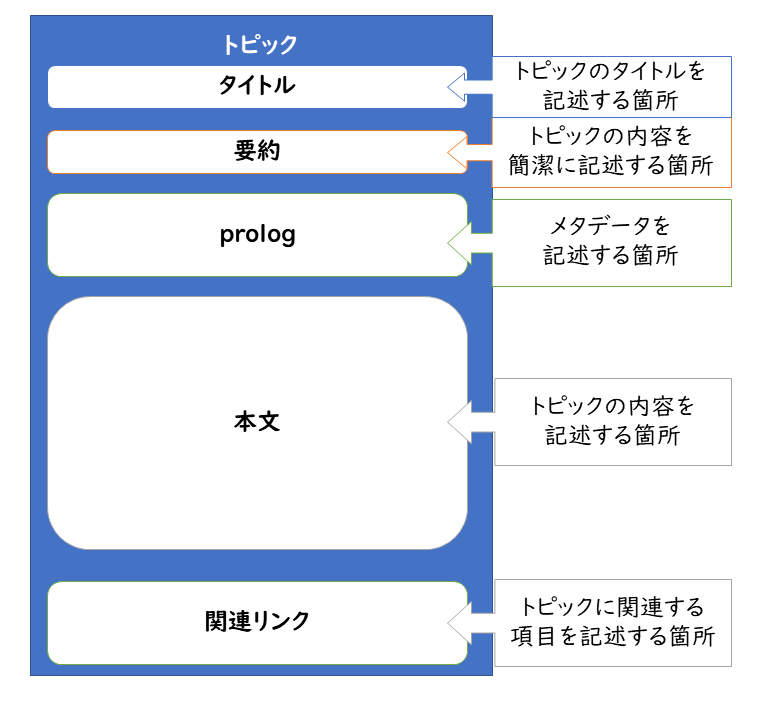
DITAではひとつのトピックファイルにはひとつのトピック(話題)しか書かない、ということが推奨されています。ひとつのトピックファイルの中でだらだらといくつもの話題に触れるのはよしましょう、ということですね。そのため、ひとつのドキュメントを制作するにあたり必然的に複数のトピックファイルを用意することになります。
トピック指向の執筆
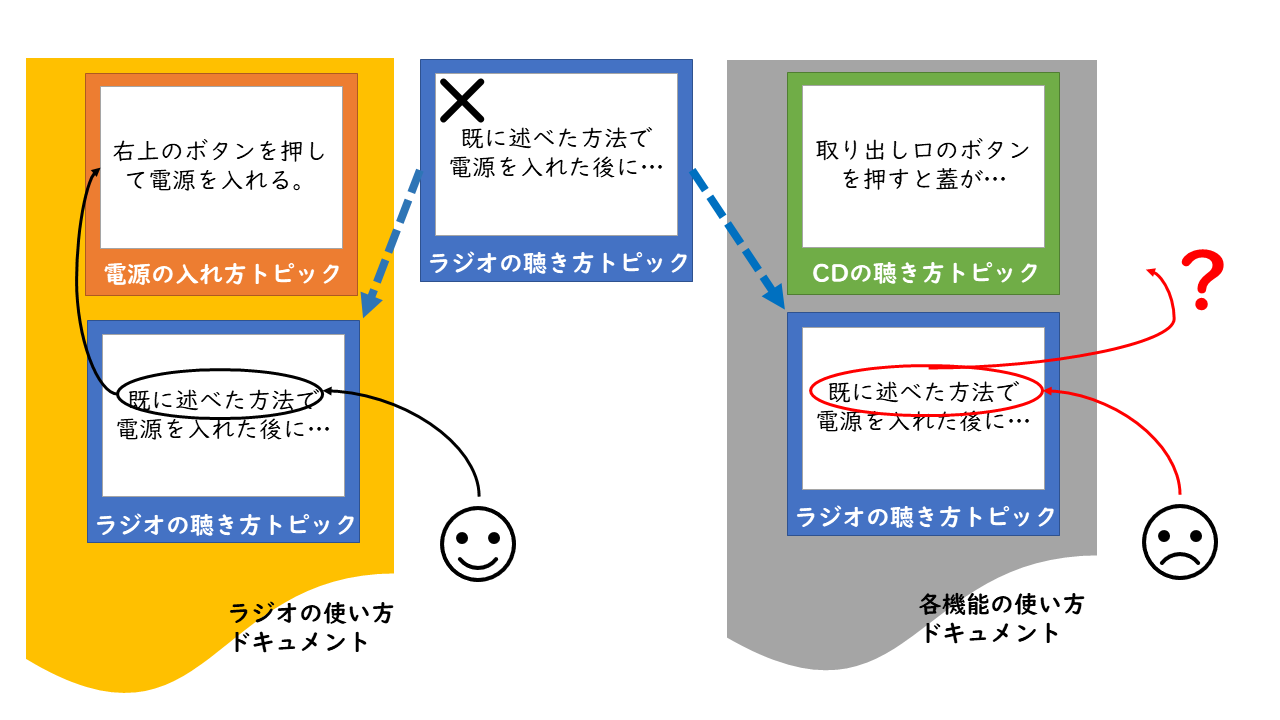
Microsoft WordやDocBookでマニュアルを書くときは、ひとつのファイルに1冊分のコンテンツを丸ごと記述します。一方DITAでは、複数のトピックファイルに分割して記述することになります。これをモジュール化といいます。こうすることで各トピックの再利用性の向上を図るわけですが、このことにより、執筆の仕方を今までとは変えなくてはならないことがあります。
たとえば「ラジオの聴き方」を書いたトピックの中では「すでに述べた方法で電源を入れた後に・・・」という書き方は避けた方がよいでしょう。なぜならマップの書き方次第では「すでに述べた」とは言い切れないからです。後で述べるかもしれませんし、そもそもどこにも述べない可能性もあります。つまり文脈依存の書き方は避けた方がよい、ということになります。これをトピック指向といいます。
ショートデスクリプション(要約)の奨め
トピック内に「ショートデスクリプション」を書くことが推奨されています。「要約(文)」と呼ぶ場合もあります。名称の通り、トピックの内容を短く説明する文を記述します。複雑な構造の文は入れられません。たとえば次のようになります。
<topic id="GoalOfDITA">
<title>DITAのめざすもの</title>
<shortdesc>DITAによってマニュアル制作の効率化を望めます</shortdesc>
<body>
<p>DITAの目的は次のとおりです</p>
<ul>
<li>データ再利用性の向上</li>
<li>ワンソースマルチユース</li>
<li>翻訳の効率化</li>
</ul>
</body>
</topic>
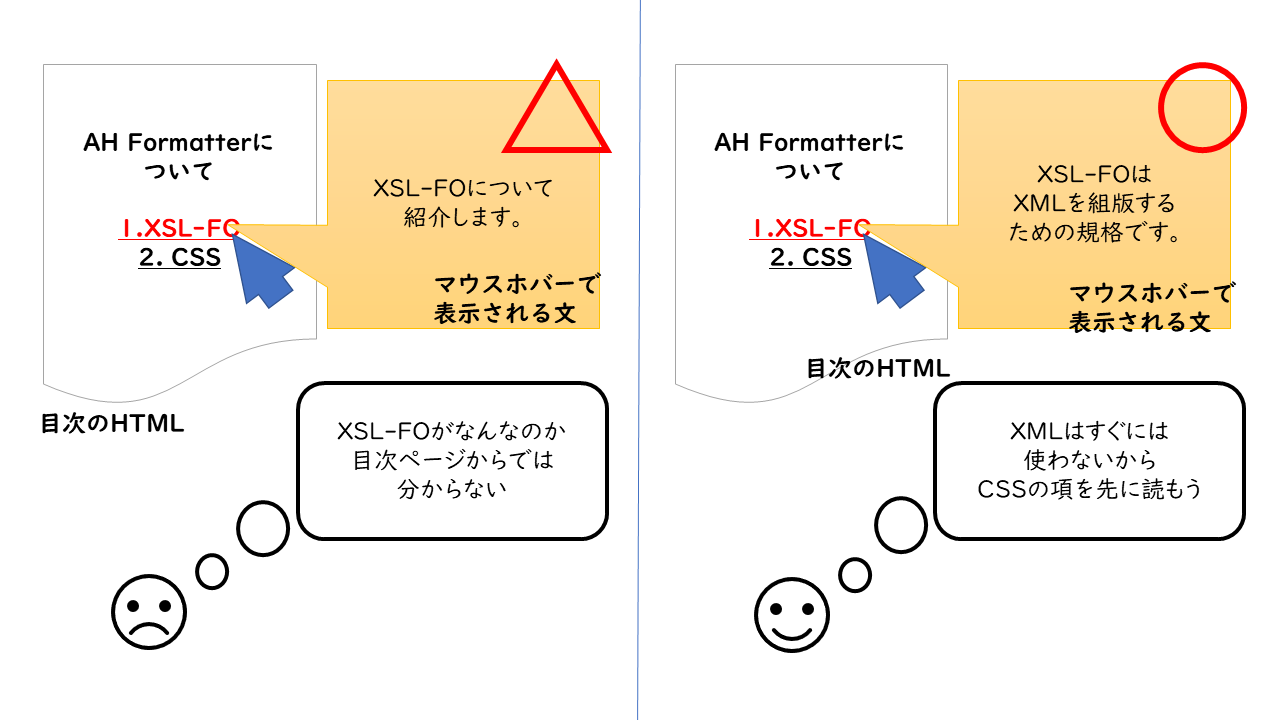
ショートデスクリプションを記述することで、次のようなことができます。
- HTMLにした際に、他のページから、このページへのアンカー文字列にマウスホバーしたときにショートデスクリプションをポップアップさせる
- 検索結果としてショートデスクリプションのみをリストアップする
とても小さなトピックの場合、「ショートデスクリプションを書くことによって本文に書くことがなくなってしまう」という心配もあるかもしれませんが、そのときは本文の方を空にします。 ショートデスクリプションを読んでそのトピックを読むべきか判断できるように記述することを心がけましょう。
マップ
トピック指向で記述された(複数の)トピックファイルを、ドキュメントに合わせてまとめることがマップの役割です。マップを使ってトピックの出力順やトピック間の階層構造を決めることになります。たとえば次のようになります。
<map title="取扱説明書">
<topicref href="はじめに.dita" />
<topicref href="電源の入れ方.dita" />
<topicref href="ラジオの聴き方.dita" />
:
:
</map>
これは基本的な例です。この他にさまざまな機能が用意されています。マップとトピックの関係を図式化すると次の画像のようになります。
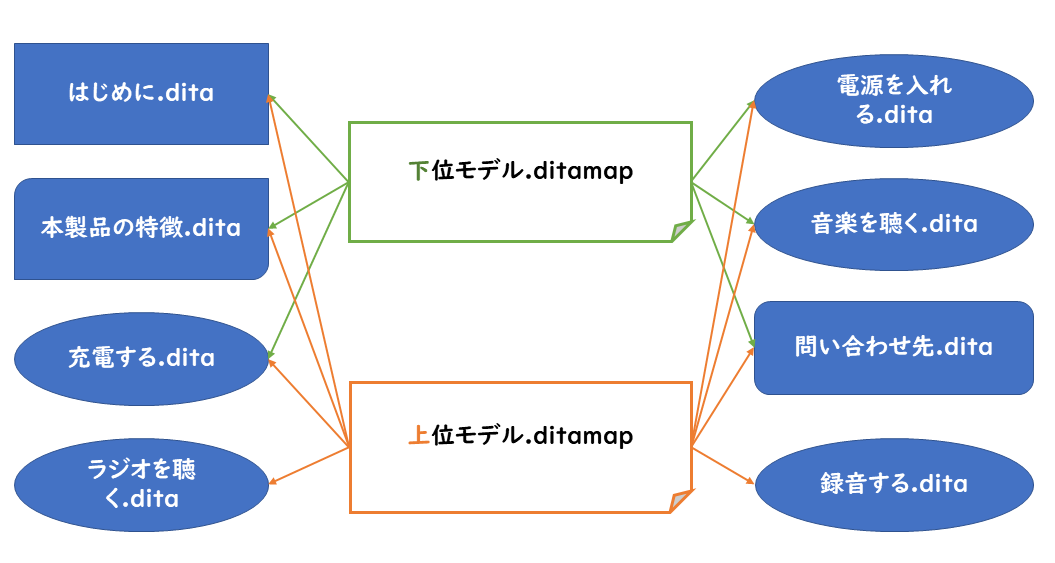
この図を見て分かるように、マニュアルの種類だけマップを作り、それぞれのマップからトピックファイルのセットを参照する、というのがDITAの基本的な考え方です。
トピックを効率的につくる「フィルタリング」「フラッギング」
ある製品Aと別の製品Bとで充電の方法が「ほんの少しだけ」異なる場合を考えてみましょう。『「トピック」と「マップ」』の話の範疇で考えると「充電の方法-A用.dita」と「充電の方法-B用.dita」のふたつを用意して、マップの中から必要な方のトピックを参照すれば無事解決です。
もちろんこの方法で間違っていません。ただ、「『ほんの少しだけ』違うだけなのにトピックを丸ごとふたつに分けるのもな~」ということもあるでしょう。そこで「条件処理(コンディショナルプロセシング)」の出番です。
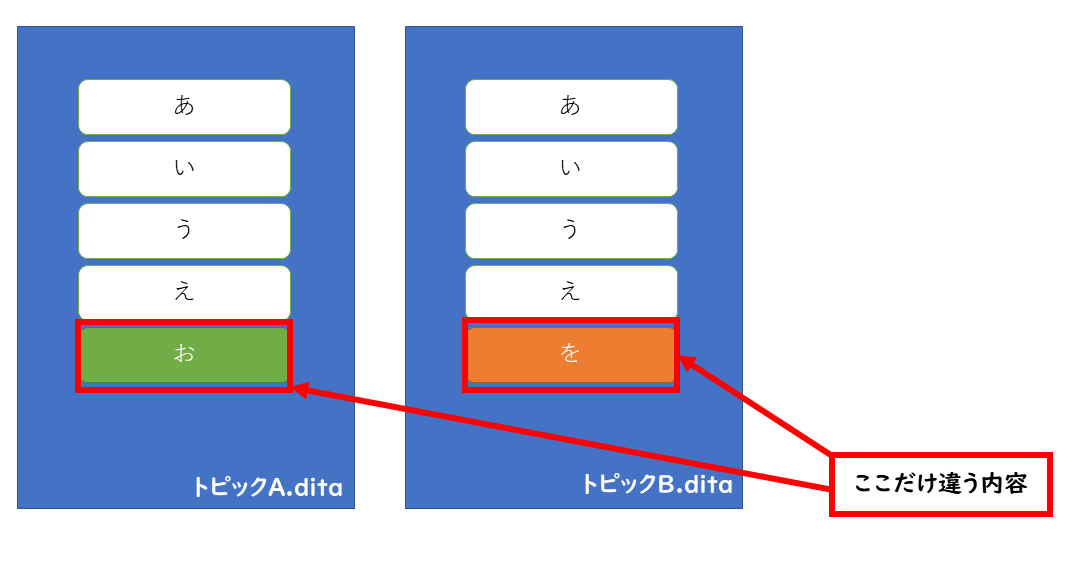
条件処理(コンディショナルプロセシング)
条件処理には、大きくふたつの機能「フィルタリング」と「フラッギング」があります。
フィルタリング
ひとつのトピックファイルの中に複数の製品の情報を混在して書いておき、マニュアル生成時にその時の条件によって、特定の情報を出力したりしなかったりをコントロールすることをフィルタリングといいます。具体例をあげましょう。
<topic id="HowToCharge">
<title>充電の方法</title>
<body>
:
:
<p product="上位モデル">
充電が完了するのに「30分」程度かかります
</p>
<p product="下位モデル">
充電が完了するのに「60分」程度かかります
</p>
<p>
充電中は電源を入れないでください
</p>
:
<body>
</topic>
このトピックには上位モデル用の充電時間と下位モデル用の充電時間が混在して書かれています。このまま何も考えずに処理すると両方ともマニュアル内に出力されてしまいます。そこで、もうひとつ、ditavalファイルというものを用意します。上位モデル用の出力を得たい場合は次のような内容にしておきます。
<val>
<prop att=”product” val=”上位モデル” action=”include” />
<prop att=”product” val=”下位モデル” action=”exclude” />
</val>
このditavalファイルでは、
- product属性が「上位モデル」のコンテンツは出力してください
- product属性が「下位モデル」のコンテンツは出力しないでください
- その他は出力してください
ということを意味しています。そしてマニュアルを作る時に、このditavalファイルを使うことを宣言すると次のような出力が得られます。
充電が完了するのに「30分」程度かかります
充電中は電源を入れないでください
下位モデル用の記述が抜け落ちています。こうすることで、「ほんの少しだけ」違うトピックを複数個作る必要がなくなります。この機能をうまく使えば、ひとつのトピックの中に「Windows向けとLinux向けの記述」であるとか「上級者向けと入門者向けの記述」であるとかを混在して書いてもよいことになりますね。
フラッギング
フィルタリングは「文字列を出力する/しない」といった分岐処理を行う際に記述されますが、「フラッギング(flagging)」は、「ある値のときは表示する文字の大きさを変える」といった加工処理を行う際に用います。 ditaval形式でファイルを用意することなどはフィルタリングと共通です。
「出力する製品のリビジョンが1.0のとき、その箇所の背景色を赤にしたい」という例を見てみましょう。
<p rev="1">
リビジョン1は2020年にサポート終了のため非推奨となっています。
</p>
<p>
リビジョン2のサポートは2022年まで続けられる予定です。
</p>
<val>
<revprop action="flag" val="1" backcolor="red" />
</val>
revpropは特にリビジョンにかかわる場合に用いるpropの亜種になります。勿論propでもフラッギング処理を行うことができます。フラッギング処理の場合、action属性に"flag"を指定し、 backcolorやunderlineといったスタイルを適用するのが基本的な記述方法です。他に、<startflag /> <endflag />を活用し、画像の表示切り替え動作も行うことができます。
特殊化
「DITA」の「D」は(進化論の)ダーウィンの頭文字です。特殊化という機能があるがゆえにダーウィンというわけです。
特殊化とは、既存のタグ・セットをベースに新しいタグ・セットを定義することです。トピック・レベルや、要素レベルで特殊化ができます。
特殊化はオブジェクト指向の継承に似ています。特殊化によって新たに定義する要素は、既存の要素の属性やコンテンツ・モデルを継承します。
たとえばDocBookでドキュメントを記述するとき、 DocBookの仕様の中で定義されている要素をそのまま使うしかありませんが、 DITAの場合は、独自の要素を定義しても構わない、とDITAの仕様として許されているのです。
もちろんある程度の制限というか作法のようなものは守らなければなりません。生物は環境に適したものが生き延びる、というのが進化論の教えるところですが、情報タイプもあなたの環境に応じたものを用意しましょう。
次のような手順を出力したい、としましょう。
- 電源スイッチを押す
- 「ラジオ」ボタンを押す
- チューニングレバーを回す
もっとも初歩的な解決方法は次のようなトピックを用意することです。
<topic>
<title>ラジオの聴き方</title>
<body>
<ol>
<li>電源スイッチを押す</li>
<li>「ラジオ」ボタンを押す</li>
<li>チューニングレバーを回す</li>
</ol>
</body>
</topic>
もちろんこれでも期待する結果は得られます。では次のような例はどうでしょうか。
<task>
<title>ラジオの聴き方</title>
<taskbody>
<steps>
<step><cmd>電源スイッチを押す</cmd></step>
<step><cmd>「ラジオ」ボタンを押す</cmd></step>
<step><cmd>チューニングレバーを回す</cmd></step>
</steps>
</taskbody>
</task>
前者は番号付き箇条書きであることは分かりますが、どういった意味の箇条書きであるのかまでは分かりません。それに対して後者の場合、単なる箇条書きではなく、何かの「手順」であるということがはっきりと分かります。このように、「それまでは<ol>を使うしかなかった状況から、(情報の質を高めるために)<steps>を使える状況に拡張」することが特殊化です。これは<ol>>に限ったことではなく、別の要素も特殊化の対象になりえます。
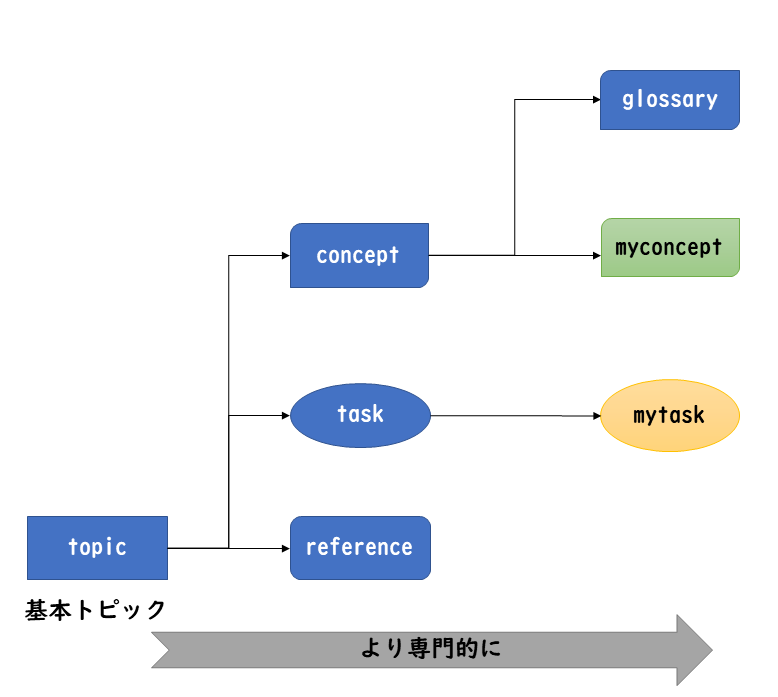
情報タイプ(トピックタイプ)
DITAにはすでに下記の「情報タイプ(トピックタイプ)」が用意されています。
汎用topic情報タイプ
DITAの出発点となる情報タイプで、HTMLライクな要素が定義されています。この情報タイプを使えばだいたいどのようなマニュアルも記述できますが、先ほど述べたように情報の質という点では劣ります。今までにいくつかのトピックサンプルを例示しましたが、すべてこの情報タイプで記述したものです。
task情報タイプ
操作手順を記述するのに特化した情報タイプです。どのような順番でどういう操作をすればどのような結果が得られるか、というようなことを記述しやすいようになっています。この情報タイプは上記の汎用topic情報タイプから派生させた(特殊化した)ものです。
DITA1.3からはtroubleshootingがtaskの中に記述できるようになりました。
concept情報タイプ
「それは何か」に対する答えを記述するのに便利な情報タイプです。たとえば「製品の特徴」や「ご使用の前に」などに利用できます。 task情報タイプでは記述できないコンテンツは大抵この情報タイプを使うことになるでしょう。この情報タイプは上記の汎用topic情報タイプから派生させた(特殊化した)ものです。
reference情報タイプ
リファレンスマニュアルを記述するのに特化した情報タイプです。この情報タイプは汎用topic情報タイプから派生させた(特殊化した)ものです。
glossary情報タイプ
用語集を記述するのに特化した情報タイプです。この情報タイプはconcept情報タイプから派生させた(特殊化した)ものです。
troubleshooting情報タイプ
DITA1.3から追加された情報タイプです。まず「症状」の記述があって、その下に「原因」と「対処法」が続く構造です。
おおよそこれらのすでに用意された情報タイプで事足りると思いますが、中にはそれでも不十分だということもあるでしょう。そのときは(上記の情報タイプから派生させる形で)自分で特殊化することになります。 画像6の「myconcept」「mytask」が、自分で特殊化を行った例です。
特殊化についての詳細は参考資料 [3] [4]をご覧ください。 日本語の参考書としては『DITA 101』[5] や 『DITA概説書』[6] があります。
その他の基本用語
フラグメント
トピックの、更に内部の要素ツリーを「フラグメント」と呼びます。再利用したい要素ツリーのトップの要素に IDを付けておくことで、conrefを使って他の箇所から参照させることができるようになります。
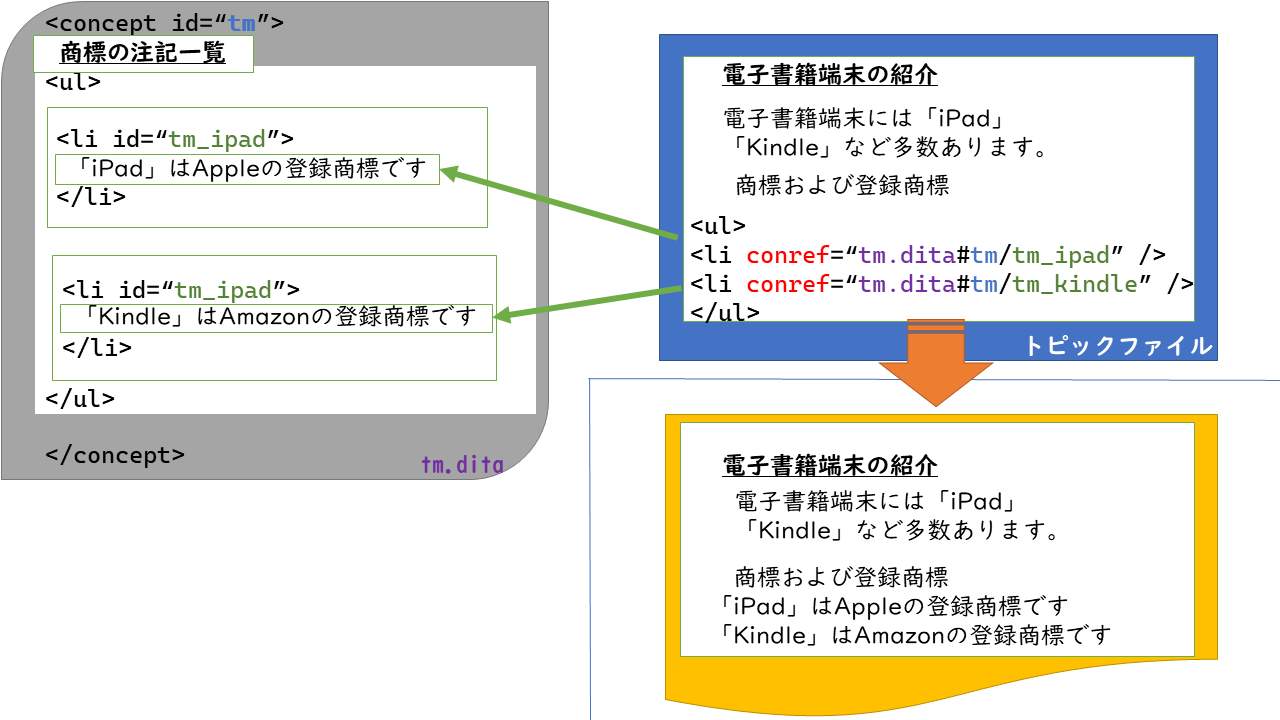
conref
条件処理を使ってコンテンツの一部を出したり出さなかったりをする方法を紹介しましたが、 conrefは他のトピックの中のほんの一部を流用する機能です(フラグメント単位での再利用)。 製品名の商標表記をひとつのトピックファイルにまとめておいて、それを参照したりするような使い方をします(画像7)。この機能によって内容を置き換えることを「トランスクルージョン(transclusion)」と呼ぶこともあります。
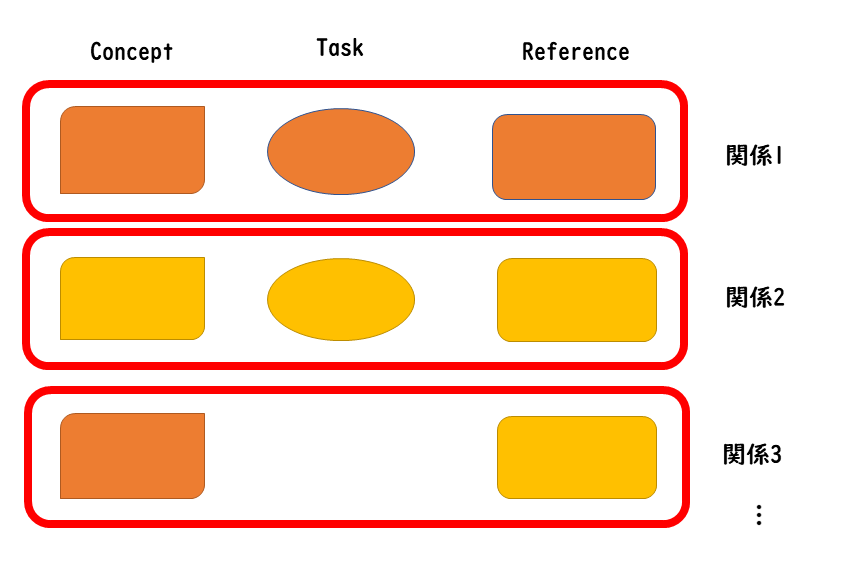
関連(性)テーブル
関連テーブルは、トピックの関連情報を記述する場所を、個別のトピックファイルからマップに移動できるしくみです。
トピックの関連情報へのリンクrelated-linksは、そのトピックの中に記述できます(画像 1「トピックの模式図」の「関連リンク」)。 関連した情報をそのトピックに直接記述することは手軽で分かりやすくはありますが、 トピック間の関係やリンク先が変更されたとき、内容を個別に変更しなくてはなりません。 関連テーブルを用いると、関連情報に変更があったときはマップだけを修正すればよいことになります。
reltableで関連付けされたリンクは、ドキュメント出力時に、トピック内にrelated-linksを書いた場合と同じように、 各トピックの関連リンクとして生成されます。
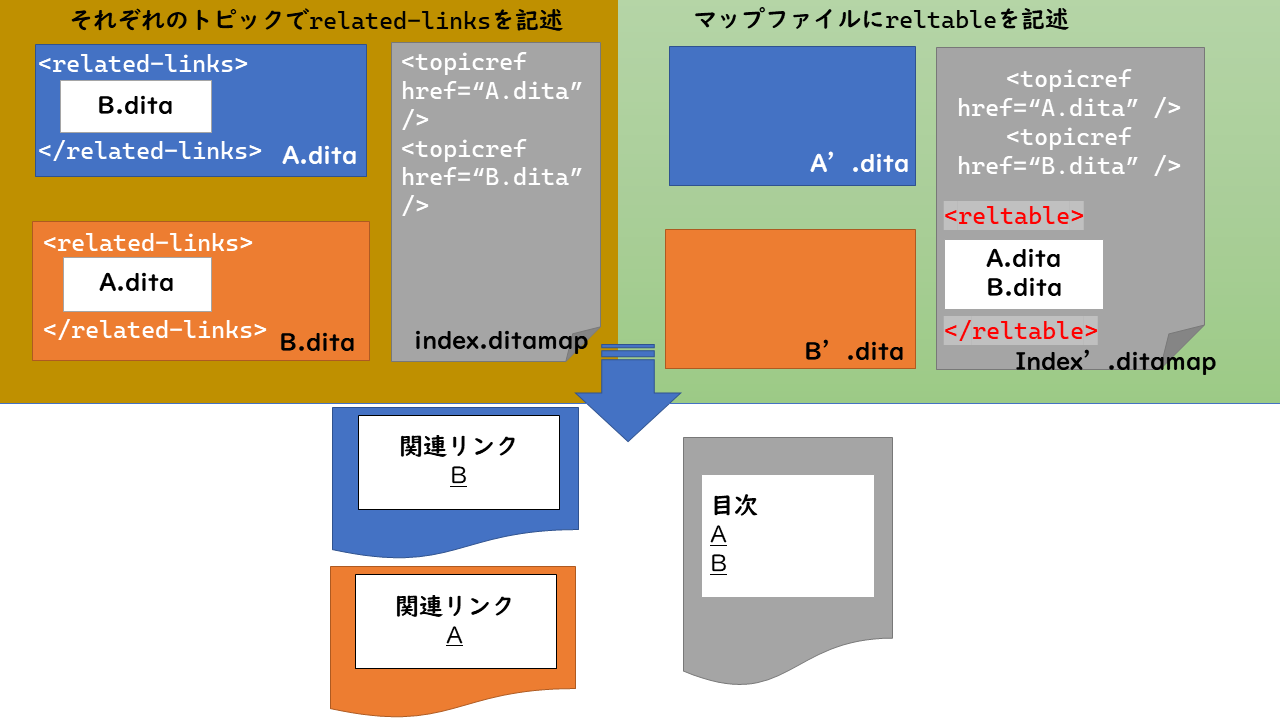
基本的には、テーブルのヘッダにトピックのタイプを並べ、それぞれの列には同じトピックタイプの文書を並べます。 同じ行にまとめたトピックが、それぞれ関連として扱われます。行と別の行は独立しています。同じセルに複数のトピックを格納することもできます。
keyref
keyrefは参照先をマップで解決しようという機能です。図式化すると次の画像?10のようになります。
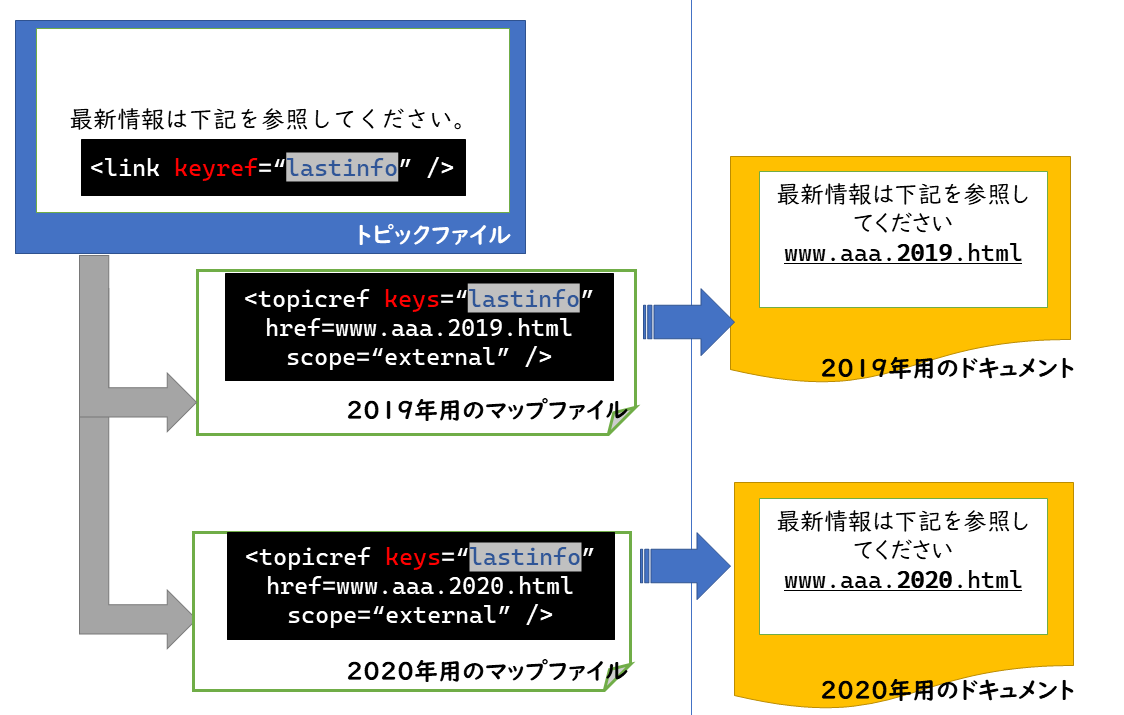
トピックの中には具体的な参照先は書かないで、マップに書き込みます。この機能はDITA1.2で追加された機能です。一度書いたトピックはできるだけ変更せずに済むように、可変データをマップに集約することができます。
画像10のように外部リンクのURLをトピックに埋め込む形から変更したり、索引を作成したりするために使うことができます。
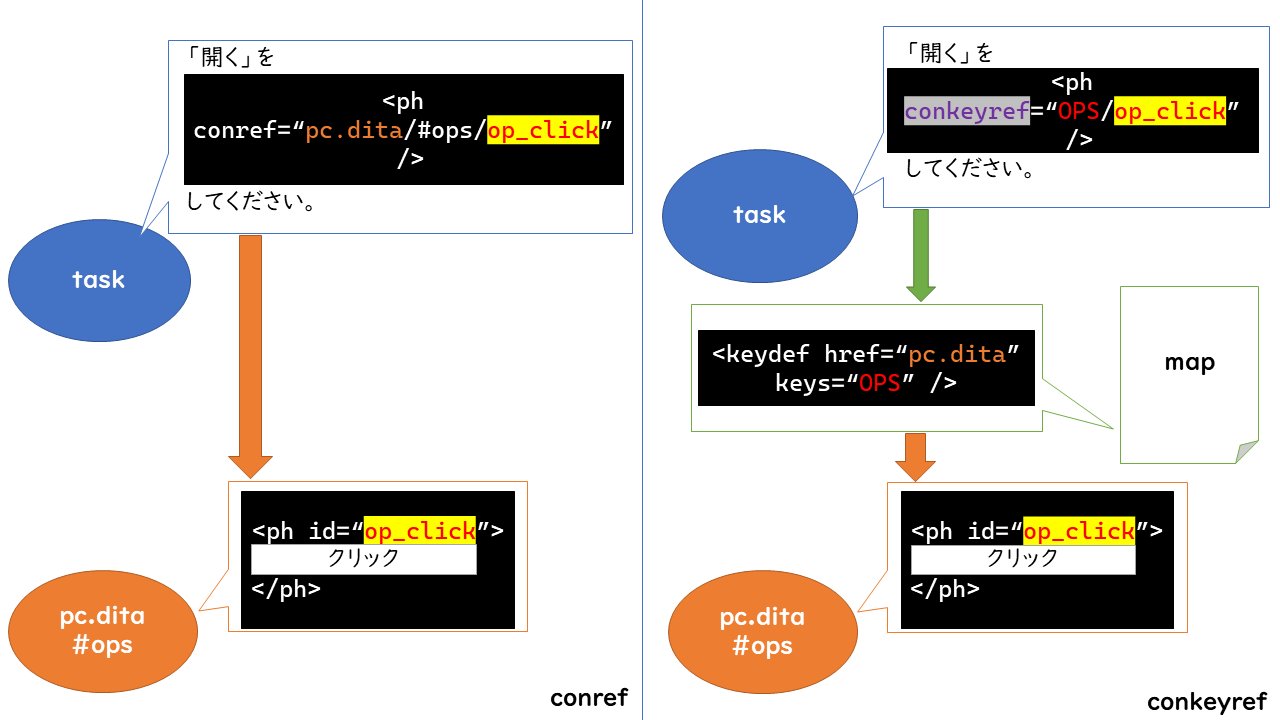
conkeyref
conrefでは参照する先のファイル名を直に記述する必要がありました。 keyrefのように、マップに参照先のファイル名を記述できれば、 参照したいファイル名が将来変わったときに、変更するのはマップだけにできますね。 画像11のようにconkeyrefはconrefでファイル名を書いていた場所をidに置き換え、 マップにidとファイルのマッピングを記述します。
参考資料
お問い合わせ
- Webフォーム
- Webフォームからお問い合わせ
- 電子メール
- sis@antenna.co.jp