操作方法
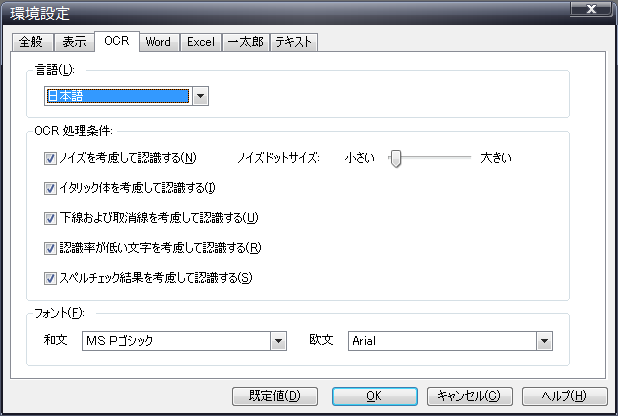
以下のOCR条件を設定できます。
言語の設定
文字認識時に参照する言語を「日本語」、「英語」のいずれかから選択します。
既定値は「日本語」です。
【ヒント】
- 日本語と英語が混在している原稿では「日本語」を選択してください。
- 英文の原稿では「英語」を選択することで、英単語の認識が正しく行われるようになります。
ノイズを考慮して認識する
画像データに黒点上の汚れ(ノイズ)がある場合、それを考慮することで認識率を上げることができます。
一般にOCR処理では、ノイズがあると誤認識の確率が高くなりますので、この設定をオンにしておくことをお勧めします。ノイズと判断する汚れの大きさをスライダーで指定することで、元データに応じた調整を行ってください。イタリック体を考慮して認識する
原稿のテキストにイタリック体が使用されていた場合、それを考慮することで認識率を上げることができます。
一般にOCR処理ではイタリック体の文字が使用されていると誤認識の確率が高くなりますので、この設定をオンにしておくことをお勧めします。下線および取消線を考慮して認識する
原稿のテキストに下線(アンダーライン)や取り消し線が使用されていた場合、それを考慮することで認識率を上げることができます。
一般にOCR処理では文字の下線や取消線があると誤認識の確率が高くなりますので、この設定をオンにしておくことをお勧めします。認識率が低い文字を考慮して認識する
かすれた文字やつぶれた文字など文字の認識率が低い画像パターンをOCR処理した場合、再度そのパターンを認識しなおすことで認識率を上げられる場合があります。
スペルチェック結果を考慮して認識する
OCR処理で認識した文字列に対して、内蔵単語辞書を使用してスペルチェックをかけることで認識率を上げることができます。
【ご注意】
- 上記の各種OCR処理条件をオンに設定されても、画像の状態によっては認識率が改善されない場合があります。
文字認識結果によっては、上記のいずれかの設定をオフにすることで良い結果が得られる場合もありますので、状況に応じて使い分けていただくことをお勧めします。
- 処理条件によっては、設定をオンにすることでOCR処理の時間が長くなる場合があります。
フォントの設定
OCR処理では、元の原稿のフォントを再現することはできません。通常は、認識したテキストに対してここで設定されたフォントが変換結果に適用されます。
お使いのパソコンにインストールされたフォント種類から、お好みのフォントを選択してください。
既定値は、和文:MSPゴシック、欧文:Arial に設定されます。
- 文字認識結果をテキストビューに表示した場合、テキストビュー上で[文字のプロパティ・ペイン]からフォントや文字サイズを個別に変更することができます。
 関連...
関連...