
簡単そうで簡単ではないPDFのテキスト抽出
更新日:

このページの目的
PDFを、Adobe Readerを始めとするPDFビューア(PDFリーダーとも)で表示し、画面上でページ全体や矩形または任意の領域のテキストを抽出したり、コピー&ペーストして再利用することがあります。
しかし、たまにコピーして取り出したテキストについて、文字やその並びなどが期待したとおりに抽出できていないということが起こります。これはなぜでしょうか。
テキストをコピー&ペーストで起きる問題
PDFを表示している画面からテキストをコピー&ペーストした結果得られるテキストが期待通りにならない原因は、大元をたどれば、PDFファイルは印刷した結果のみを保証するものだからです。そう言ってしまうと終わりですので、原因を考えながら現象を整理してみます。現象は次の4つに分類できそうです。
- PDFファイルにはテキストの順序、またはつながりの情報がなく、つながりの認識が難しい
- 異なるブロックの文字が、ブロックを跨がってつながってしまい、文脈がおかしくなってしまう
- 表の行と列、セルの内容がつながってしまい、表として使えない
- 図形やグラフなどからテキストの断片が取り出せるが、意味が理解できない状態となる
- 抽出したテキストでは文字の順番が、元のPDFの表示順と異なっている
- 表示されているテキストの文字コードが取得できない
- 画面に表示されている文字の中にコピーできない文字がある(ペーストすると一部の文字が脱落してしまう)
- ペーストした結果を表示すると、元のPDFを表示したときの文字とは別の文字(字の形が化けている)になっている
- PDFファイルを作るときの文字の見栄え・修飾を表現する仕方が原因
- ペーストすると文字が2重になっている
- ペーストしたテキストに、元のPDFの表示では見えていない文字が混ざっている
- PDFで文字の位置を指定する方法上、テキストの並びが画面上(見た目)と、PDFファイル内部では違うため
- ペーストしたテキストの文字間に、もともとなかった空白や改行が入ってしまう
- 元のPDFを表示すると文字間に空きがあるのに、ペーストしたテキストでは空きが詰まってしまう
- PDF表示では空きのない文字間に、ペーストすると空白が入っている
- ペーストしたテキストに、PDFでは別の位置に表示されている文字が混ざり込んでいる
テキストの順序、またはつながりの認識が難しい
印刷された文字をテキストで表現するには、どういう順序でテキスト化するかを決める必要があります。紙の上にレイアウトされた文字の並びに適切な順序を指定するのは、必ずしも簡単ではありません。

PDFに限らず印刷物での一連の文字は、行頭から始まり、行末へ流れます。 文の途中で行末に至ると次の行の行頭へ移り、再び行末へ流れます。こうした文字の流れを目で追うことで、自然に文字を、意味を持つひとかたまりの情報として捉えられるようになります。
では、PDFはどうでしょうか。
PDFのテキスト抽出に必要なこと
- 文字の流れと行の流れ
- 画面上で開いたPDFのある特定のページ全体、またはページ内の特定の矩形領域を選択してその中の文字を外部に取り出すとき、取り出した文字を、文章の流れに従って一列に並べる必要があります。このためには、表示された特定の領域内にある文字と行の進行方向のほか、領域内の行頭と行末を認識することが必要です。
- ブロック構成の順序
-
- ページ内が段組み、コラム、表、図などのブロックで分割・構成されているとき、ブロックとして適切に認識すること。
- コピー元として複数のブロックを選択したとき、異なるブロックのテキストを混合しない。
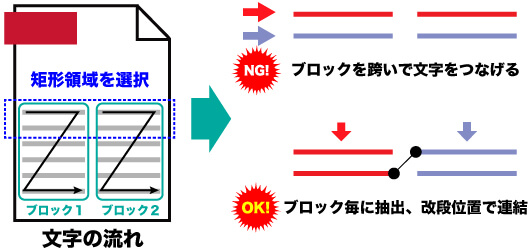
例えば、選択した矩形領域の中でテキストが二段組で配置されているときは、2つの段のテキストは改段の位置でのみ繋げなければ意味のあるテキスト抽出になりません。
また、選択した矩形領域が左右にフロートで配置されているブロックを含むときは、本文のテキストとフロートで配置されているブロック内のテキストは分離させておかなければ、やはり意味のあるテキストは抽出できません。
- 本文以外の情報と区別する
- 一般に、印刷用PDFのテキストは基本版面と版面外に分離できます。ページの上下(稀に小口)に配置される柱やノンブルと基本版面の本文とは分離する必要があります。
- 表の場合
- セル単位に文字を区切る必要があります。ブロックと同様に、異なるセル内のテキストを繋げてはいけません。
- 注の扱い
- 傍注(横書きの場合)、頭注(縦書き)などは、本文中の語句の補助的な説明文で、「本文」ではないため、本文の文字とは区別するべきでしょう。
表示されているテキストの文字コードが取得できない!?
ごくたまに、PDFビューア上でコピー操作はできるのに、メモ帳などにペーストすると、文字化けしてしまうPDFに出会います。
PDFを画面上で表示したとき、文字は線画またはビットマップ画像で表されています。これを、「字形」(グリフ)といいます。PDF上の文字を外部にテキストとして取り出すには、字形から文字コードに対応付けができなければなりません。
仮に、テキストの文字コードをUnicodeで表そうとした場合、画面上の文字(字形)には、テキストファイルではUnicodeのコード番号(コードポイントとも)への対応付け(対応テーブルの用意)が必要になります。
ですが、必ずしもビューア画面上の文字(字形)が、Unicodeの文字コードと適切に対応付けられているわけではありません。どういう場合に起こりうるでしょうか。
- PDFにはフォントが埋め込まれているが、PDFの内部に字形と文字コードの対応テーブルが用意されていないとき。
- PDF内部で字形と文字コードの対応テーブルが独自に設定されている(カスタムエンコーディング)とき。

PDFのプロパティ表示例 - 文字がアウトライン化されてしまっているとき。
- Unicodeの私用領域(外字領域とも)の文字コードが使われているとき。
- 記号類など、同じ記号がUnicodeにもあるが、PDFでは字形ではなく「画像」として埋め込まれているとき。
これ以外にも、たまに原因不明で文字が化けてしまうことがあり、本当に一筋縄ではいかないPDFのテキスト抽出です。
PDFで文字の見栄え・修飾を表現する仕方が原因
古いPDFでは、強調指定の文字は文字を少しずらして2重打ちして表現しています。するとコピー&ペーストしたとき、二重にテキストが取得されてしまいます。
また、アウトライン文字を表現するのに同じ文字を重ねて表現することがあります。そうすると、単純なテキスト抽出では文字が2重に抽出されてしまいます。
また、文字の色を下地と同じ色にしたり、透明にすればPDFを表示したときにはその文字は見えません。この部分をテキスト抽出すると、抽出結果にはもともとなかった文字が現れます。
テキストの並びが画面上(見た目)と、PDFファイル内部で違っている
PDFでは文字を印刷する位置を、文字単位でページ上のどこにでも指定できます。印刷する位置とはPDFビューアが画面上に表示する位置です。PDFファイルの中で順番になっている2つの文字が、最初の文字の表示位置はページの左上、次の文字の表示位置はページの右下であって問題はありません。
多くのPDFビューアでは、PDFファイルからテキストを取り出すとき、ファイル内に格納されている順番で取り出しています。実は、この「ファイル内に格納されている順番」というのが曲者で、必ずしも画面上で表現されるような順番になっているわけではないのです。
これは、どういうことでしょうか?
PDFファイルの内部のテキストはPDFファイルの制作ソフトの都合の良いように格納されています。その格納の順序が、テキストを取り出すときの順番として利用されるため、抽出した際のテキストの順番が、時々意図したとおりの並びになっていなかったりするのです。
しかし、これは画面上の見た目で順序が異なることを見つけることはできず、コピーして取り出したテキストをメモ帳などにペーストして結果を見てみないことにはわかりません。
次の簡単な例を示します。
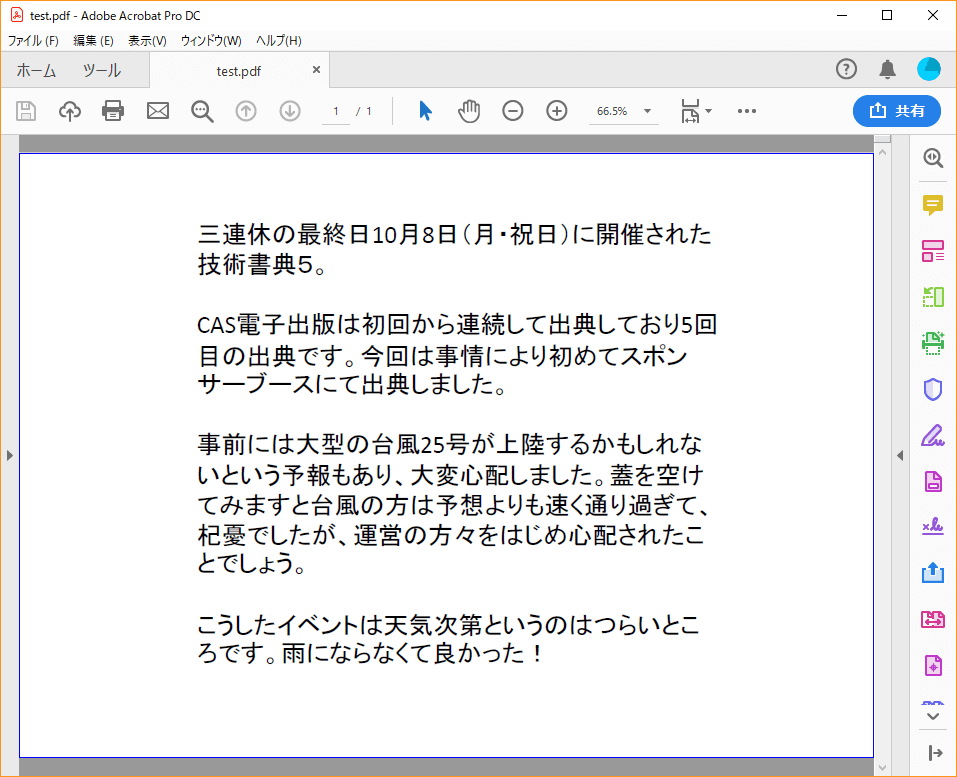
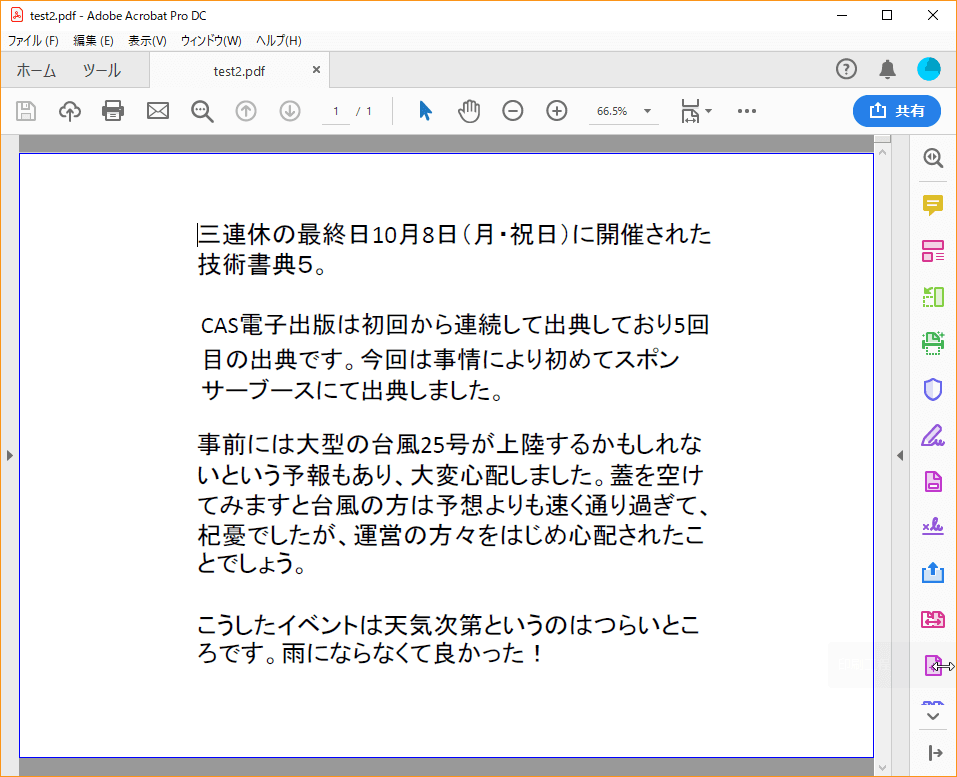
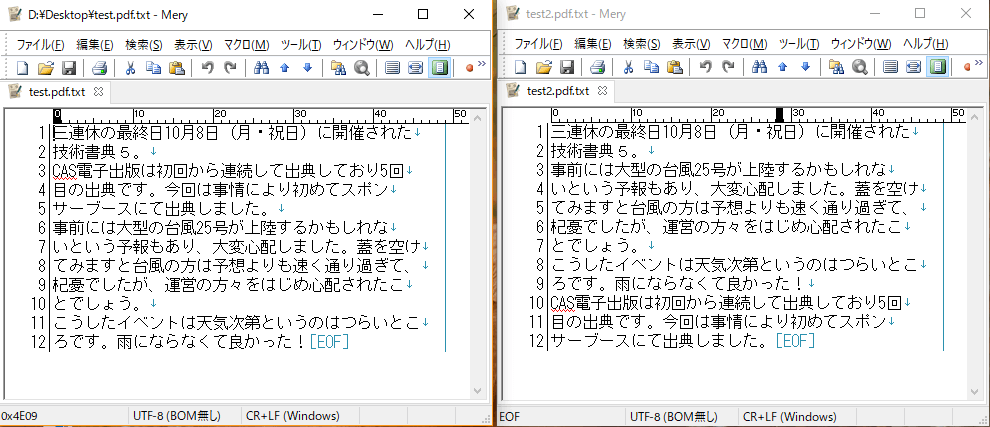
上図は、PDFビューアで「test.pdf」「test2.pdf」を並べてみた画像です。見る限り、両者には全く差がありません。しかし、これを全文コピー&ペーストしてみると、2つのPDFファイルから取り出したテキストの順番が違うことがわかります。
(参考)電子書籍、電子出版のCAS-UBブログ
簡単そうで難しいPDFからのテキスト抽出 解決策を考えます