OCRオプションの設定方法
OCRオプションの設定を変更するには、以下の2通りの選択方法があります。
- 変換処理全体でOCRオプションを設定する:[ツール]バーから[OCR条件の既定値(R)...]を選択して表示されるダイアログボックスから設定します。ここで設定した内容は、ファイルリストビューに登録されたすべてのファイルのOCR設定条件初期値として使用されます。
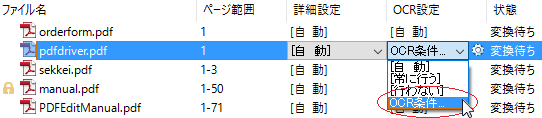
- ファイル個別にOCRオプションを設定する:ファイルリストビューで任意のファイルを選択し、OCR設定欄をクリックして表示されるプルダウンメニューから「OCR条件...」を選択します。ここで設定した内容は、ファイル個別の設定として、変換処理全体で設定されたOCR設定条件より優先して使用されます。
OCRオプション
以下のダイアログボックスから指定します。
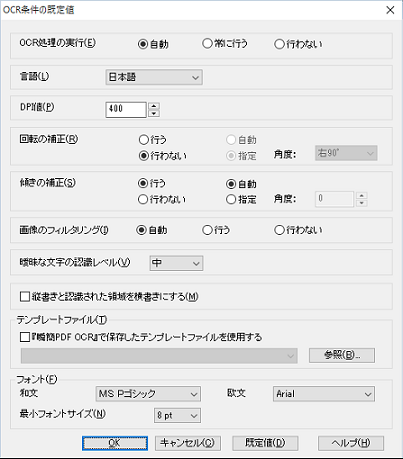
- OCR処理の実行:OCR処理を実行するか否かについて設定します。変換形式として「OCR結果をPDFファイルに埋め込む」が選択されている場合、この設定は無視され、常にOCR処理が行われます。
- 自動:PDFファイルのページ毎にOCR処理を行うかどうかを判断しながら処理します。ページ上に文字データが存在する場合には、OCR処理を行なわず、通常の変換処理を行います。この場合、画像データは画像のまま変換先に移ります。また、ページ上に画像データだけしか存在しない場合にはOCR処理を行います。この場合、OCR処理による文字認識で文字が出力されます。
- 常に行う:PDFを画像データとして扱い強制的にOCR処理を実行します。この場合、PDFのページ内で文字と認識できるデータは通常の文字として出力されます。
- 行わない:OCR処理を行いません。PDFファイルのページ中の画像は画像のまま出力されます。
- 言語:OCR処理対象となる文書の言語を指定します。
- 日本語:対象を日本語の文書としてOCR処理します。
- 英語:対象を英語の文書としてOCR処理します。この場合、元データ中に日本語の文字があると文字化けして変換されます。
- DPI値:本製品では、OCR処理を行う際、一旦対象となるページをビットマップ画像に変換します。ここで設定するDPI値は、このとき作成する画像の解像度で、96~500DPIの範囲で設定します。
【ヒント】
- 一般的に解像度が低いと文字の認識率は低下し、解像度が高いと逆に認識率は高くなります。しかし、高解像度に設定した場合、画像作成に長時間を要すと共に処理に大量のメモリを必要とするため、場合によってはこの画像作成処理に失敗する可能性もあります。通常は、300~400DPIの範囲を指定して処理してください。
- 画像の回転:処理対象となるページの向きが回転している場合、これを補正することができます。なお、このオプションは、処理対象が画像ファイルの場合のみに有効です。PDFファイルの場合には、変換詳細設定で指定します。
- 行う:回転補正を行います。
- [自動]を選択した場合、OCR処理の際に自動的にページの回転方向を判断します。但し、画像の状態により、ページの回転方向を正しく判断できない場合があります。
- [指定]を選択した場合、回転補正角度をラジオボタン右のコンボボックスを使って、[右90°]/[左90°]/[180°]のいずれかで指定します。
- 行わない:回転補正を行いません。
- 傾き補正:処理対象となるページが傾いている場合、これを補正することができます。通常は、「自動」を選択します。
- 行う:傾き補正を行います。補正角度は、自動で行うか、±45°の範囲を1°単位で指定して行うことができます。
- 行わない:傾き補正を行いません。
- 画像のフィルタリング:OCR処理対象となる画像にあるノイズを除去するためにフィルタリングするか否かについてを設定します。通常は、「自動」を選択します。
- 自動:画像の状況を判断して自動的にフィルタリング処理を行います。
- 行う:フィルタリング処理を行います。画像の状況によっては、ノイズと共に文字部分が除去されることもあります。
- 行わない:フィルタリング処理を行いません。
- 曖昧な文字の認識レベル:曖昧な文字についての認識レベルの設定を行います。変換形式として「OCR結果をPDFファイルに埋め込む」が選択されている場合、この設定は無視されます。
- 縦書きと認識された領域を横書きにする:処理対象となるページが横書きであるにも関わらず、文字の並び位置が縦方向に揃っていると縦書きの領域と誤認されることがあります。このような場合に強制的に横書きの領域に変更することができます。
- テンプレートファイル:姉妹製品『瞬簡PDF OCR』で作成/保存されたテンプレートファイルの読み込みを指定します。
- OCR処理では、画像上でテキストや表として変換したい部分を別の領域として誤認識してしまう場合があります。本製品の既定値ではそのようなときに誤認識したままOCR処理を行うため、文字化けなどが生じてしまいます。このような場合は、「OCR補正機能」を使用することで、画面上の操作により誤認識した領域を正しい領域に補正して、誤変換を改善することができます。
- [『瞬簡PDF OCR』で保存したテンプレートファイルを使用する]:テンプレートファイルを読み込む場合は、チェックをつけてください。ここにチェックをつけることで、テンプレートファイル名の指定が可能になります。
- [テンプレートファイル名]:お使いのパソコンに姉妹製品『瞬簡PDF OCR』がインストールされ、テンプレートファイルが保存されている場合には、ここにファイルの一覧が表示されます。一覧から任意のファイルを選択してください。

- フォント:文書ファイル中で用いる和文/欧文フォントそれぞれと設定される文字の最小フォントサイズを指定します。ここで指定したサイズ以下の文字は、最小フォントサイズで出力します。変換形式として「OCR結果をPDFファイルに埋め込む」が選択されている場合、これらの設定は無視されます。