【Word/ Excel/ PowerPoint】

- Word/ Excel/ PowerPont 2007-2016 文書(*.docx/*.xlsx/*.pptx):Microsoft Word/ Excel/ PowerPoint 2007 以降の形式で出力します。
- Word/ Excel/ PowerPont 97-2003 文書(*.doc/*.xls/*.ppt):Microsoft Word/ Excel/ PowerPoint 2003 以前の形式で出力します。
【注意!】
Word/ Excel/ PowerPont 2007-2016 文書を指定し、実行環境にJavaがインストールされていない場合は、インストール手順を案内する以下の画面を表示します。
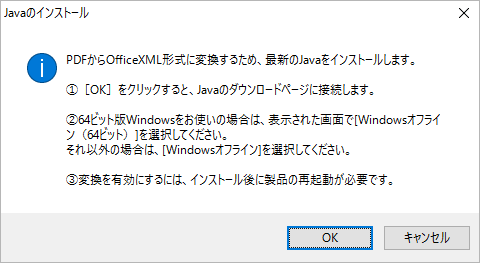
- Javaのダウンロードページに接続して、お使いのWindowsに適合したJava(32ビット版または64ビット版)をインストールしてください。
- 設定を有効にするには、いったん製品を再起動してください。
【OCR】

- OCR結果をPDFファイルに埋め込む:OCR処理によって得られたテキストをPDFファイルに埋め込み、出力します。
- OCR結果をテキストとして出力:OCR処理によって得られたテキストをテキストファイルに出力します。
【抽出】

- テキストを抽出:PDFファイル中のテキストを抽出し、テキストファイルに出力します。
- 画像を抽出:PDFファイル中の画像データを抽出し、個々に画像ファイルとして出力します。
【注意!】
[OCR結果をPDFファイルに埋め込む]を指定した場合、OCRオプションの設定が無効となり、以下に示す通りに機能します。
- [変換設定]→[PDFの出力方法]の指定が「既定値(元データを画像化してOCR結果を埋め込む)」の場合
- [OCR処理の実行]が[行わない]に設定されていると、画像をそのまま出力します。
- 言語、dpi値、回転補正、傾き補正、画像のフィルタリング、フォント名の各指定:参照します。
- 上記以外の各指定:参照しません。
- [変換設定]→[PDFの出力方法]の指定が「元データの情報を保持してOCR結果を埋め込む」の場合
- [OCR処理の実行]:PDF内のテキストでない箇所に対して常にOCR処理を行います。
- 言語、dpi値、フォント名の各指定:参照します。
- 上記以外の各指定:参照しません。