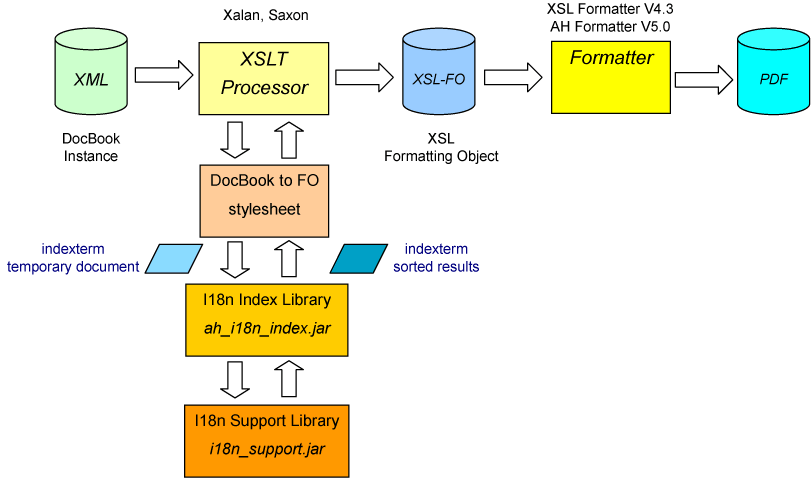
[Fig.1] Processing Diagram
| Date | Contents | Reviser |
|---|---|---|
| Jun 04, 2009 | Newly published. | T.Makita |
Antenna House I18n Index Library is a Java library that makes index pages in the various languages used by the DocBook to XSL-FO stylesheet.
- Implements many DocBook indexterm features using XSL1.1 index functions.
- Supports 21 language indexes including CJK.
| Catalan, Czech, Danish, German, English, Spanish, Finnish, French, Hungarian, Italian, Dutch, Norwegian, Polish, Portuguese, Russian, Swedish, Turkish, Simplified Chinese, Traditional Chinese, Japanese, Korean |
- Supports major Java based XSLT processors.
- Includes sample XSLT stylesheet for DocBook to XSL-FO transformation.
- You can use the sortas attribute to correct Simplified Chinese index orders.
For example the Chinese word "粘贴" belongs to "N" index group because the most common reading of "粘" is "nian2". However the correct reading is "zhan1" for this word.
<indexterm><primary>粘贴</primary></indexterm>
You can correct this problem by specifying the correct reading (pinyin) to the sortas attribute value. The fix will place "粘贴" into the "Z" index group.
<indexterm><primary sortas="zhan1 tie1">粘贴</primary></indexterm>
The processing diagram for using the I18n Index Library follows:
[Fig.1] Processing Diagram
| Item | Contents |
|---|---|
| Java Runtime Environment | Sun JRE1.4 or later |
| XSLT Processor | Saxon 6.5, Xalan 2.7 or Saxon-B 9 |
| XML Parser | Xerces 2.x (I18N Support Library uses this processor. Included in this release.) |
| XSL Formatter | Antenna House XSL Formatter V4.3 or Antenna House Formatter V5.0 |
This section describes how to make a sample PDF using the included batch files.
Please select an XSLT processor from Saxon 6.5.5, Xalan 2.7.1, or Saxon-B 9.1, and then download it from the following URL.
| XSLT Processor | URL | Comments |
|---|---|---|
| Saxon 6.5.5 | http://saxon.sourceforge.net/ | Also works if you want to use Saxon 6.5.3 |
| Xalan 2.7.1 | http://xml.apache.org/xalan-j/ | |
| Saxon-B 9.1 | http://saxon.sourceforge.net/ | Saxon-B is an opensource XSLT processor. Saxon-SA 9.1 is a schema-aware commercial processor. |
After downloading the archive, unzip it into an appropriate folder.
Modify the startcmd.bat batch file according to the selected XSLT processor. Rewrite the following values to correspond to the location where the .jar file was saved. Not all XSLT processors are needed.
SET SAXON6_HOME=%PROJECT_HOME%xslt\saxon6-5-5
SET XALAN2_HOME=%PROJECT_HOME%xslt\xalan-j_2_7_1
SET SAXON9_HOME=%PROJECT_HOME%xslt\saxonb9-1-0-6j
For instance, if you want to test using SaxonB-9 only, rewrite SAXON9_HOME environmental variable and comment out the other lines.
REM *** Example ***
REM SET SAXON6_HOME=%PROJECT_HOME%xslt\saxon6-5-5
REM SET XALAN2_HOME=%PROJECT_HOME%xslt\xalan-j_2_7_1
SET SAXON9_HOME=C:\MY_DOWNLOAD\xslt\saxonb9-1-0-6j
Next, please rewrite the following line according to your Formatter environment.
REM AHF Formatter, XSL Formatter home
SET AHF_HOME=C:\Program Files\Antenna\XSLFormatterV43
REM SET AHF_HOME=C:\Program Files\AntennaHouse\AHFormatterV5
run_en.bat [saxon6 | xalan2 | saxon9]
[Fig.2] Example of running a batch file
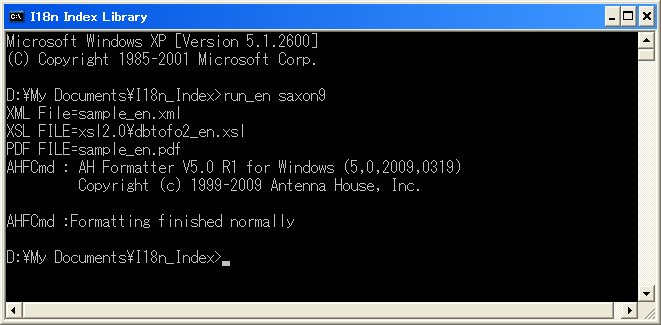
The result of sample_en.pdf is saved to the current folder.
[Fig.3] English output PDF sample
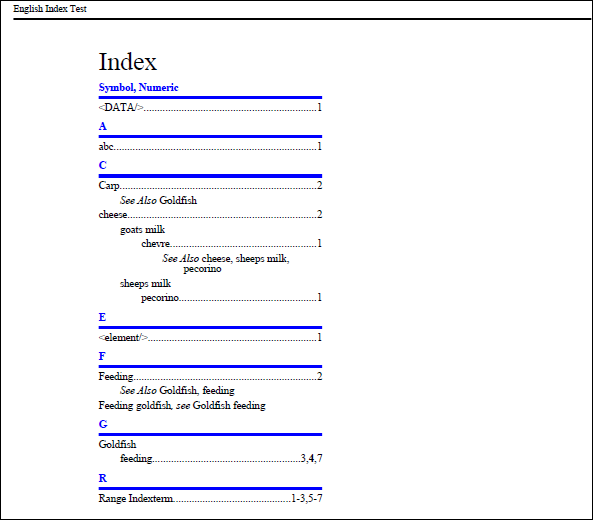
By running the batch files, you can confirm the following features:
| Batch File | PDF File | Feature | Used Font |
|---|---|---|---|
| run_en.bat | sample_en.pdf | DocBook and XSL 1.1 features;
|
Times New Roman |
| run_zhcn_normal.bat | sample_zh_cn1.pdf | Simplified Chinese (zh-CN) index feature; Index is sorted by following keys and grouped by the first character of the pinyin.
Pinyin/Strokes/Radical/GB2312-90 Code Order |
SimHei |
| run_zhcn_sortaspinyin.bat | sample_zh_cn2.pdf | Simplified Chinese index correction using sortas attribute feature; As Chinese Hanzi has multiple readings sometimes the index entry is not placed into the correct index group. To solve this problem we set the correct reading to the sortas attribute. By doing this, the following words will be placed into the correct index group position.
|
SimHei |
| run_zhtw.bat | sample_zh_tw.pdf | Traditional Chinese index feature; The index is sorted by the following keys and grouped by strokes.
Strokes/Radical/Big5 Code Order |
MingLiu |
| run_ja.bat | sample_ja.pdf | Japanese index feature; The Japanese index uses sortas for its readings. Index are sorted by sortas order and grouped by consonants. For more details see original XML file sample_ja.xml. | MS Mincho |
| run_ko.bat | sample_ko.pdf | Korean index feature; The Korean index is sorted by its syllable block order and the index is grouped by the consonant of the first character. | Batang |
This library has XSLT1.0 and XSLT2.0 sample stylesheets in the stylesheet folder. These stylesheets create XSL-FO from DocBook instance. Each stylesheet file has the following role. (XSLT1.0 stylesheet has the prefix "dbtofo". XSLT2.0 stylesheet has the prefix "dbtofo2".)
| File | Contents |
|---|---|
| dbtofo.xsl | Shell stylesheet that includes other needed stylesheet files. |
| dbtofo_attributeset.xsl | Stylesheet that contains all xsl:attribute definitions. |
| dbtofo_const.xsl | Stylesheet that contains global variables. |
| dbtofo_content.xsl | Stylesheet that manipulates main DocBook elements. |
| dbtofo_global.xsl | Stylesheet that defines data/parameter dependent global variables. |
| dbtofo_index.xsl | Stylesheet that passes indexterm element to the library and make index page from results. |
| dbtofo_indexterm.xsl | Stylesheet that checks indexterm integrity and generates fo:wrapper element and XSL1.1 indexkey property. |
| dbtofo_main.xsl | Stylesheet that contains main control template. |
| dbtofo_param.xsl | Stylesheet that contains parameter. |
| dbtofo_en.xsl dbtofo_ja.xsl dbtofo_ko.xsl dbtofo_zhcn.xsl dbtofo_zhcn_sortaspinyin.xsl dbtofo_zhtw.xsl |
Language wrapper stylesheet that imports dbtofo.xsl. |
| xslt_common.xsll | Stylesheet that supply XSLT processor information. (XSLT1.0 only) |
The most important stylesheet files are dbtofo_indexterm.xsl and dbtofo_index.xsl. The core index processing algorithms is integrated into these two stylesheets. You can make modifications to this stylesheet or import them into your stylesheets.
The library ah_i18n_index.jar has following static method for the stylesheet (XSLT processor).
| XSLT processor | Class | Method |
|---|---|---|
| Xalan 2.7 | jp.co.antenna.ah_i18n_index.IndexSortXalan2 | public static org.w3c.dom.DocumentFragment indexSortXalan2(String lang, org.w3c.dom.NodeList nodeList) |
| public static org.w3c.dom.DocumentFragment indexSortXalan2(String lang, org.w3c.dom.NodeList nodeList, String assumeSortasPinyin) | ||
| Saxon 6.5.5 | jp.co.antenna.ah_i18n_index.IndexSortSaxon6 | public static org.w3c.dom.NodeList indexSortSaxon6(String lang, com.icl.saxon.expr.FragmentValue indextermInfo) |
| public static org.w3c.dom.NodeList indexSortSaxon6(String lang, com.icl.saxon.expr.FragmentValue indextermInfo, String assumeSortasPinyin) | ||
| Saxon-B 9 | jp.co.antenna.ah_i18n_index.IndexSortSaxon9 | public static org.w3c.dom.NodeList indexSortSaxon9(String lang, org.w3c.dom.Node indextermInfo) |
| public static org.w3c.dom.NodeList indexSortSaxon9(String lang, org.w3c.dom.Node indextermInfo, String assumeSortasPinyin) |
The first parameter is a language code defined in RFC3066. It should be the main language of the input document.
The second parameter differs by XSLT processor. It must be the same temporary document (Result Tree Fragments in XSLT 1.0) created from the indexterm element. The content has the following element structure.
<!-- Indexterm element in source document -->
<indexterm>
<primary>cheese</primary>
<secondary>sheeps milk</secondary>
<tertiary>pecorino</tertiary>
</indexterm>
<indexterm>
<primary sortas="element"><element/></primary>
</indexterm>
↓
<!-- Temporary document passed to library -->
<index-data indexkey="cheese:sheeps milk:pecorino" level="3" nestedindexterm="0" significance="normal">
<indexterm>cheese</indexterm>
<indexterm>sheeps milk</indexterm>
<indexterm>pecorino</indexterm>
</index-data>
<index-data indexkey="<element/>" level="1" nestedindexterm="0" significance="normal">
<indexterm sortas="element"><element/></indexterm>
</index-data>
The third parameter is a string that indicates to use sortas attribute as pinyin reading. This parameter value should be 'true' or 'false'. The default value is 'false' and this parameter can be omitted.
☞ NOTE: Refer to the JavaDoc in the javadoc folder or db2fo_index.xsl stylesheet source file for details.
In this mode, the sortas attribute is the assumed pinyin reading. So you can correct irregularly positioned indexterm like following.
<!-- Illegaly positioned indexterm in index page (粘贴 belongs N group)--> <indexterm> <primary>粘贴</primary> </indexterm> ↓ <!-- Corrected indexterm (粘贴 belongs Z group) --> <indexterm> <primary sortas="zhan1 tie1">粘贴</primary> </indexterm>
But there are other uses for sortas. For example, you might want place "<element/>" indexterm to E group or you might want to treat "β测试" (β testing) as "测试". In this case, please modify the source document as follows.
<!-- sortaspinyin="false" mode -->
<indexterm>
<primary sortas="element"><element/></primary>
</indexterm>
<indexterm>
<primary sortas="测试">β测试</primary>
</indexterm>
↓
<!-- sortaspinyin="true" mode ("∆" means space) -->
<indexterm>
<primary sortas="e∆l∆e∆m∆e∆n∆t"><element/></primary>
</indexterm>
<indexterm>
<primary sortas="�∆ce4∆shi4">β测试</primary>
</indexterm>
Because sortas attribute is assumed as pinyin readings, Hanzi character must be specified as pinyin and Non-Hanzi character can be used as is. However in both cases, pinyin or Non-Hanzi characters must both be separated by a space. And in the latter example, you must insert U+FFFD (REPLACEMENT CHARACTER) instead of "β" character. This is because, the "β" character is not included in sortas attribute. U+FFFD is a placeholder of such character.
< END OF DOCUMENT >