製品概要
- テキスト抽出機能
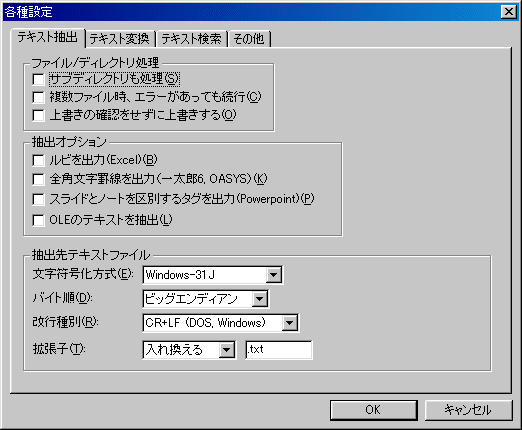
文書を作成したアプリケーションが無くても、文書を直接読み込んで、テキスト部分だけを抜き出すことができます。
また、OLEオブジェクトからもテキスト文字列を抽出できます。
- テキスト変換機能
テキストファイルの文字符号化方式や改行コードの種別を変換することができます。
- テキスト検索機能
作成した文書を格納した場所や、ファイル名が解らなくても、文書に含まれる文字列を指定することで、希望するファイルを検索することができます。
|
動作環境
CPU:インテルx86系(WindowsNTの場合)
対応OS:Microsoft Windows95/98/Me/2000/NT4.0
※Windows2000/NT4.0の場合、Administratorの権限がないとインストールできません。
※本ソフトはクライアントライセンス専用です。
対象ファイル
Microsoft Word V6/V7(95)/97/98/2000/mac 2001
Microsoft Excel V4/V5/V7(95)/97/2000/98 for Macintosh/mac 2001
Microsoft PowerPoint 95/97/2000/mac 2001
Microsoft RTF 1.3/1.4/1.5
Microsoft Works 2000(文書/表/データベース)
Adobe Acrobat PDF 1.2/1.3
Adobe PageMaker 6.0/6.5
富士通 OASYS V3/4/5/6/7/8 分離形式
富士通 OASYS V3/4/5/6/7/8 OA2形式
富士通 OASYS V5/6/7/8 OA3形式
富士通 OASYSオンライン形式
Lotus 1-2-3 97/98/MillenniumEdition9.5/2000/OASYS 1-2-3
Lotus 1-2-3 R5
JUSTSYSTEM 一太郎 V6/V6.3/dash2
JUSTSYSTEM 一太郎 7/8/9/lite/10
Claris Mac WriteII
Claris ClarisWorks 4
Apple AppleWorks 6
Corel WordPerfect Office 2000 (WordPerfect 8/9 のみ)
HTML
XML
AutoCAD R13/LT95/R14/LT97 DXF(ASCII形式/Binary形式)
AutoCAD 2000 DXF(ASCII形式/Binary形式)
AutoCAD R13/LT95/R14/LT97 DWG
AutoCAD 2000 DWG
IGES
※表やデータベースファイルは、CSVファイルとして出力されます。
OLEテキスト抽出対象ファイル
Microsoft Word Ver6/95/97/98/2000/mac 2001
Microsoft Excel Ver4/5/95/97/2000/98 for Macintosh/mac 2001
Microsoft Powerpoint 95/97/2000/mac 2001
Microsoft RTF 1.3/1.4/1.5
Microsoft Works 2000(文書/データベース)
Adobe PageMaker 6.0/6.5
JUSTSYSTEM 一太郎 7/8/9/10
AutoCAD R13/LT95/R14/LT97 DXF(ASCII形式/Binary形式)
AutoCAD 2000 DXF(ASCII形式/Binary形式)
AutoCAD R13/LT95/R14/LT97 DWG
AutoCAD 2000 DWG
※OLEテキスト抽出とは、例えばWord文書の中に貼りついているExcel文書のテキストを抽出できます。
抽出するかどうかは、設定する事が可能です。
出力テキストとして指定可能な文字符号化方式
Shift_JIS
WINDOWS31J
EUC-JP
EUC-JP-FIX
ISO-2022-JP
ISO-10646-UCS-2
ISO-10646-UCS-4
UTF-8
UTF-16
ISO8859-1 |
制限事項
- パスワードで保護されたファイルからのテキスト抽出、変換、検索はできません。あらかじめオリジナルのアプリケーションでパスワードを解除していただく必要があります。
- PDFのテキスト抽出ファイルの制限
Windows版Acrobat3/4/5内に組み込まれている「PDFWriter」「Distiller」で出力されたPDFファイルのみ対応しています。その以外のPDFに関しては、文字化け/抽出エラー等が発生する可能性があります。
共通仕様
制御コードについて
- ワープロ本文中の制御コードのうち、TAB 、改行コード以外の制御コードは削除します。
定義外文字
- 抽出先の符号化方式で使われる基本文字集合にない文字は類似の文字(1 文字または1 文字の組合せ)にマップします。
- 類似の文字が無い場合は、"〓"(2 バイト)、"?" (1 バイト)に置き換えて出力します。
ユーザ外字
- 抽出先の符号化方式でユーザ定義文字を使用可能な場合、アプリケーションのユーザ外字領域の先頭から順番に、ユーザ定義文字領域にマップします。
- 抽出先の符号化文字集合で、ユーザ定義文字を使用できない場合は、アプリケーションのユーザ外字は、"〓"(2 バイト)、"?" (1 バイト)に置き換えて出力します。
OLEオブジェクト抽出
- OLEオブジェクトの3階層まで抽出できます。4階層以上の場合、エラーとなります。
ワープロに関する仕様
全角文字罫線
- 全角文字罫線(一太郎Ver.6、OASYS、OASYSオンラインのみ有効)についてアプリケーションが全角文字罫線(罫線の高さが1
行を占め、幅が全角1 文字分を占める罫線)を使用している場合、全角文字罫線を出力する/しないを設定で切りかえることができます。
- 全角文字罫線を出力する場合は、文字罫線コードに置き換えて出力します。
- 全角文字罫線を出力しない場合は、全角空白コードに置き換えて出力します。
その他の罫線について
表について
制限事項
- 図形、イメージ、線画、枠、数式は無視します。
- Word、RTF文書に挿入された自動更新の日付、時間は正しく抽出できません。
- Word、RTF文書の特殊文字は一部抽出できません。
- Word、RTFファイルのフィールドの内容は一部抽出できません。
プレゼンテーションファイルに関する仕様
- プレゼンテーション・ファイルからは、スライドとノートのテキストを抽出します。
スライド番号は抽出しません。
スライドとノートを区別するタグの出力について
- 各種設定で「タグを出力する」を指定した場合、抽出時に以下のタグを付加して出力します。
<slide>、</slide>、<notes>、</notes>などのタグを出力します。
タグの出力仕様
スライド1:<slide></slide>
スライド2:<slide></slide>
・
・
・
スライドn:<slide></slide>
ノート1:<notes></notes>
ノート2:<notes></notes>
・
・
・
ノートn:<notes></notes> |
※ スライド毎に<slide></slide>でスライドからの抽出データを括り、ノートからの抽出データを<slide>外に順番に出力します。
表計算に関する仕様
- 表計算形式ファイルからテキストを抽出し、CSV 形式でテキストファイルに出力します。
行
- ワークシートの一行を文字列の一行として出力します。
- 行は上から順に出力します。
- 一行の終了には改行コードを出力します。
- データが存在しない行は改行コードのみ出力します。
列
- 一行内の出力は、列の先頭から列順に出力します。
- 列間は「,」で区切ります。
- データの無いセルは、データ無しとして出力します。 この場合「前セルデータ,後セルデータ」といった形で、「列区切りのカンマ」が連続して出力されることになります。 但し、データが後ろに続かない場合は、最後の「,」は出力しないものとします。
セル
- 文字データセルは「"」で括って出力します。 出力する文字列に「"」が含まれる場合は「\」でエスケープして出力します。
- フォント、配置、罫線、パターン書式は全て無視します。
- 色属性以外の表示書式は、反映して出力します。表示書式を反映した場合に、数値データセルであるにも関わらず数値文字でない文字が含まれてしまう場合は、文字列として「"」で括って出力します。 (指数表現など)
- 数値文字は「0 ~9 」の数値と符号である「+」「-」と小数点「.」から構成される文字列です。 符号は先頭になければなりません。 また、小数点は数値文字列中に一つしか存在してはなりません。
- 数値は10 進数で表現されるものとします。
- セル内改行コードは無視し、行を連結して出力します。
シート
以下の形式のファイルは抽出対象外となります。
- テンプレートファイル
- アドインファイル
- ワークシートが含まれないブックファイル
- セル値レコードをなにも含まないワークシート
-
含まれているワークシートすべてが変換対象で無いブックファイル
Excel抽出の制限事項
- ヘッダとフッタでは、指定された頁番号、頁数、日付、時刻、ファイル名、シート名を抽出しません。
-
「シートの保護」を設定したファイルが抽出できますが、「ブックの保護」を 指定したファイルの抽出はできません。
PDFに関する仕様
- 文字と改行位置に不適当な場合があります。
- 抽出されたテキストの順番は必ずしもPDF の表示結果と一致しません。
- ユーザ定義Cmap文字は抽出できない場合があります。または、symbol文字は文字化けする場合があります。
- 立体文字に設定されている文字が、3重に出力されます。
- LZW圧縮されたテキスト部分はテキストを抽出できません。
CADに関する仕様
- テキストの抽出はその格納する座標値によって順序を並べます。優先順序はY-X-Zです。
-
データ間は区切りません。
HTMLに関する仕様
- タグと属性を無視して、タグと属性以外の文字列を抽出します。
-
<TITLE>....</TITLE>間の文字列は、本文と区別するため、{....}ように抽出されます。
XMLに関する仕様
- 文書の先頭に文字列<?xml version="1.0" ....?>があるファイルのみXMLファイルと認識します。(判定条件)
- XMLファイルでスタイルシートファイルを指定した場合、そのスタイルシートファイル中のテキストをテキストファイルの先頭に抽出します。
- タグと属性を無視して、タグと属性以外の文字列を抽出します。
-
ルビ文字がルビかぶられた文字列の後ろに続いて出力します。
Macintoshに関する仕様
- Office 2001:Mac、Excel98は、Appleのユーザ定義文字の抽出は保証できません。
|
|